Real world에 강화학습을 진행하다보면 넘어야 할 많은 허들이 있다.
몇 가지 생각을 해 보면 (실시간 학습은 못 해봐서 내가 풀었던 문제들에 한해서는)
1) Real world와 유사한 시뮬레이터를 제작해야 하고
2) 아무리 유사하다고 해도 실제 real world를 완벽하게 반영하기 어렵다. (sim2real)
3) Reward design을 하다보면 sparse reward한 경우가 많다.
4) action space가 복잡한 경우가 많다.
등등.. 이 있는 거 같다.
최근 푸는 문제에서는 모든 action을 해 봐야 정확한 피드백을 줄 수 있는 문제여서
episode가 다 끝나기 전까지는 각 step의 action이 좋은 건지 안닌지 판단하기가 애매하다.
거기다가 episode length도 거의 100 ~ 300이 되기 때문에 100 ~ 300의 action을 모두 끝내기 전까지는
reward가 0으로 들어가는 큰 문제가 있다.
지금 내가 고민하고 있는 문제는 large action space에 대한 exploration 문제이고 credit assignment를 어떻게 해결할까 이다.
그래서 이거 저거 찾아보고 있는데, 정답은 없지만 그냥 기록은 해보려고 한다.
0. Background
RL Korea를 통해 검색 키워드 도출
첫 번째 글이랑 슈퍼마리오 관련 게시글이 좀 인상깊었는데, 정리하자면
1) 휴리스틱한 리워드를 추가해서 step reward를 최대한 줘본다
2) curiosity, intrinsic reward 같이 exploration bonus reward를 추가한다.
3) rudder 처럼 lstm으로 trajectory를 트레이닝 시킨 후 hidden state를 reward로 사용한다.
정도가 일반적으로 많이 사용하는 방법들인 거 같다.


기본 용어
Non-episodic : continuous task로 명확한 끝이 없이 계속 이어지는 task를 의미함. 예를 들어 주식 같은 환경이 non-episodic 일 거 같음
episodic : 명확한 시작과 끝이 있음. 예를 들어, 미로 찾기가 episodic task일 것 같음. 명확한 시작점에서 도달해야 하는 끝 점이 있는 task
Intrinsic reward : 내부에서 발생하는 reward (the reward to get right away)
Extrinsic reward : 외부에서 발생하는 reward (the reward to induce exploration)
1. 방법론들
아래 페이지만 봐도 대부분의 방법론들을 알 수는 있을 거 같다. 쭉 읽어봤는데 RL Korea에서도 언급되었던 RND가 있고, 요즘 curiosity RL쪽 Sota라는 NGU(never give up)도 설명되어 있다.
Exploration Strategies in Deep Reinforcement Learning
Exploitation versus exploration is a critical topic in reinforcement learning. This post introduces several common approaches for better exploration in Deep RL.
lilianweng.github.io
Classic Exploration 방법론들
- Epsilon-greedy : agent가 random exploration을 진행할 때 probability ϵ을 활용하는 방법론.
- Upper confidence bounds : agent가 upper confidence bound를 최대화할 수 있는 greediest action을 선택.
- Boltzmann exploration(softmax) : boltzmann distribution을 활용하여 action을 샘플링함.(선택)
- Thomson sampling : cumulative rewards 를 최대로 하는 action을 찾는 문제를 몇 가지 condition을 추가하여 Bayes' Thm.으로 MAP로 정의하는 것(블로그 참고).
- Entropy loss term : loss function에 entropy term H를 추가하여 다양한 action을 취할 수 있도록 유도함.
- Noise-based Exploration : observation과 action에 noise를 추가하는 방법.
Intrinsic Reward as Exploration Bonuses
원문이 좋아서 그대로 가져와봤다.
요지는 reward로 extrinsic reward와 intrinsic reward의 조합을 사용하는 것 같고,
intrinsic reward는 exploration을 위한 bonuse로 사용이 된다고 한다.
아직 실제로 적용해보지는 않았지만, 만약 이렇게 사용한다고 하면 β를 튜닝하는데에 시간이 은근 걸릴 거 같다.
exploration bonuse를 사용하더라도 내가 의도하는 reward 자체는 sparse하기 때문에 원하는 성능까지 끌어올리기 위해서는 상당한 시간 학습을 시켜야 할텐데, 여기서 β 튜닝까지 들어가면 초반 시행착오 하는 시간이 많이 들지 않을까..
그래도 exploration을 유도하면서 좋은 action을 찾을 가능성을 높인다는 측면에서 시도해볼 가치가 있다.

RND(Random Network Distillation)
논문 : https://arxiv.org/abs/1810.12894
Exploration by Random Network Distillation
We introduce an exploration bonus for deep reinforcement learning methods that is easy to implement and adds minimal overhead to the computation performed. The bonus is the error of a neural network predicting features of the observations given by a fixed
arxiv.org
위에서 간단하게 설명했던 intrinsic exploration bonus 개념을 적용한 논문이다.
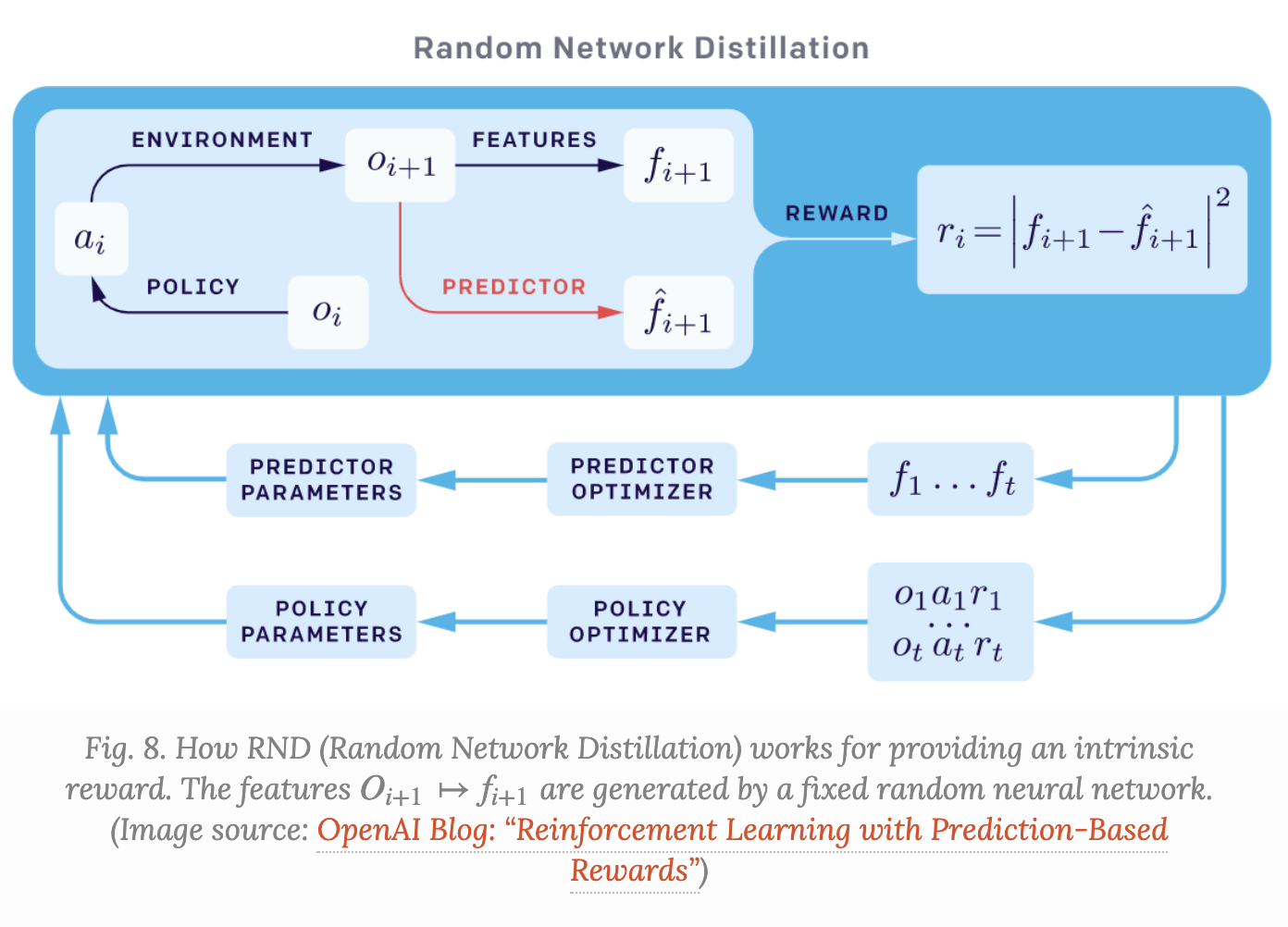
이 논문에서는 prediction error(curiosity)를 bonus로 사용했다고 한다.
조금 더 구체적으로 설명하자면 target network와 predictor network에서 나온 state feature의 차이를 reward로 주어 학습하는 논문이다.
이때 target network는 fixed randomly intilized network이고 초기 weight를 고정시켜서 사용하기 때문에 같은 state에 대해서는 항상 같은 feature를 추출하는 deterministic function이다. 그래서 기존 ICM에서 존재했던 stochastic 문제(동일 state라도 next state가 변할 수 있다)를 해결한다고 한다.
predictor network는 agent에 의해 수집된 데이터로 학습하여 feature를 예측하는 network 이다.
즉 predictor network를 target network와 유사하게 점점 학습시켜 나가는 방법론이고,
key point는 prediction error가 predictor가 학습한 것과 다른 novel state에 대해서는 높은 값을 가지게 되면서 exporation을 높이는 방향으로 학습하게 되는 거 같다.
장점으로는 1) 구현이 쉽고 2) computation performed가 적게 든다는 점이 있다.
github : 링크
GitHub - jcwleo/random-network-distillation-pytorch: Random Network Distillation pytorch
Random Network Distillation pytorch. Contribute to jcwleo/random-network-distillation-pytorch development by creating an account on GitHub.
github.com
위 github 코드를 보면 next_obs를 이용해서 target_next_feature와 predict_next_feature를 구하고 이를 이용해 intrinsic reward를 계산하고 있다.
def compute_intrinsic_reward(self, next_obs):
next_obs = torch.FloatTensor(next_obs).to(self.device)
target_next_feature = self.rnd.target(next_obs)
predict_next_feature = self.rnd.predictor(next_obs)
intrinsic_reward = (target_next_feature - predict_next_feature).pow(2).sum(1) / 2
return intrinsic_reward.data.cpu().numpy()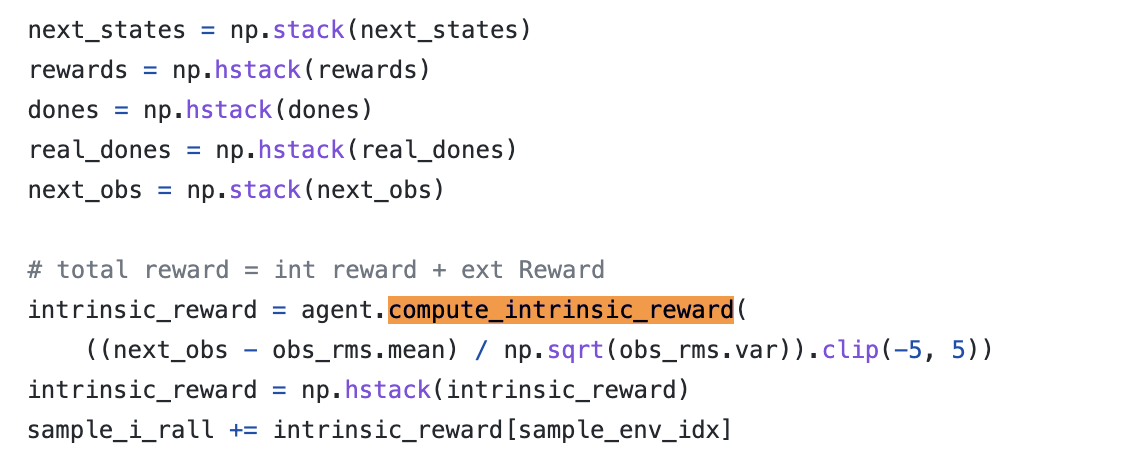
그리고 train 코드에서 위와 같은 식으로 extrinsic reward와 intrinsic reward를 결합하여 사용할 수 있는 구조를 구현하면 되는 거 같다.
논문에 나와있는 것처럼 구현 자체는 좀 쉬운 편인 거 같다 보인다.
episodic return과 non-episodic return을 결합해서 사용했다고 하고 이를 잘 조합해서 사용하기 위해 discount rates를 활용하고 있다. (관련 코드는 캡쳐하지 않은 뒷 부분에 있음)
non-episodic return = intrinsic reward
episodic return = extrinsic reward 인 거 같다. ( 확신은 없는데 의미적으로 predictor 에서 얻은 return은 episode와 상관없이 쭉 학습하는 것이기 때문에 non-episodic reward라고 생각이 된다)
NGU(Never Give Up)
논문 : https://paperswithcode.com/paper/never-give-up-learning-directed-exploration-1
NGU는 RND 논문에서 episodic novelty module을 추가하여 성능을 높인 논문이다.
RND는 non-episodic setting에서 더 나은 방법론이고 NGU는 RND에서 episodic novelty module을 결합하여 episodic setting에서도 효율성을 높인 게 아닐까?(하는 내 생각..)
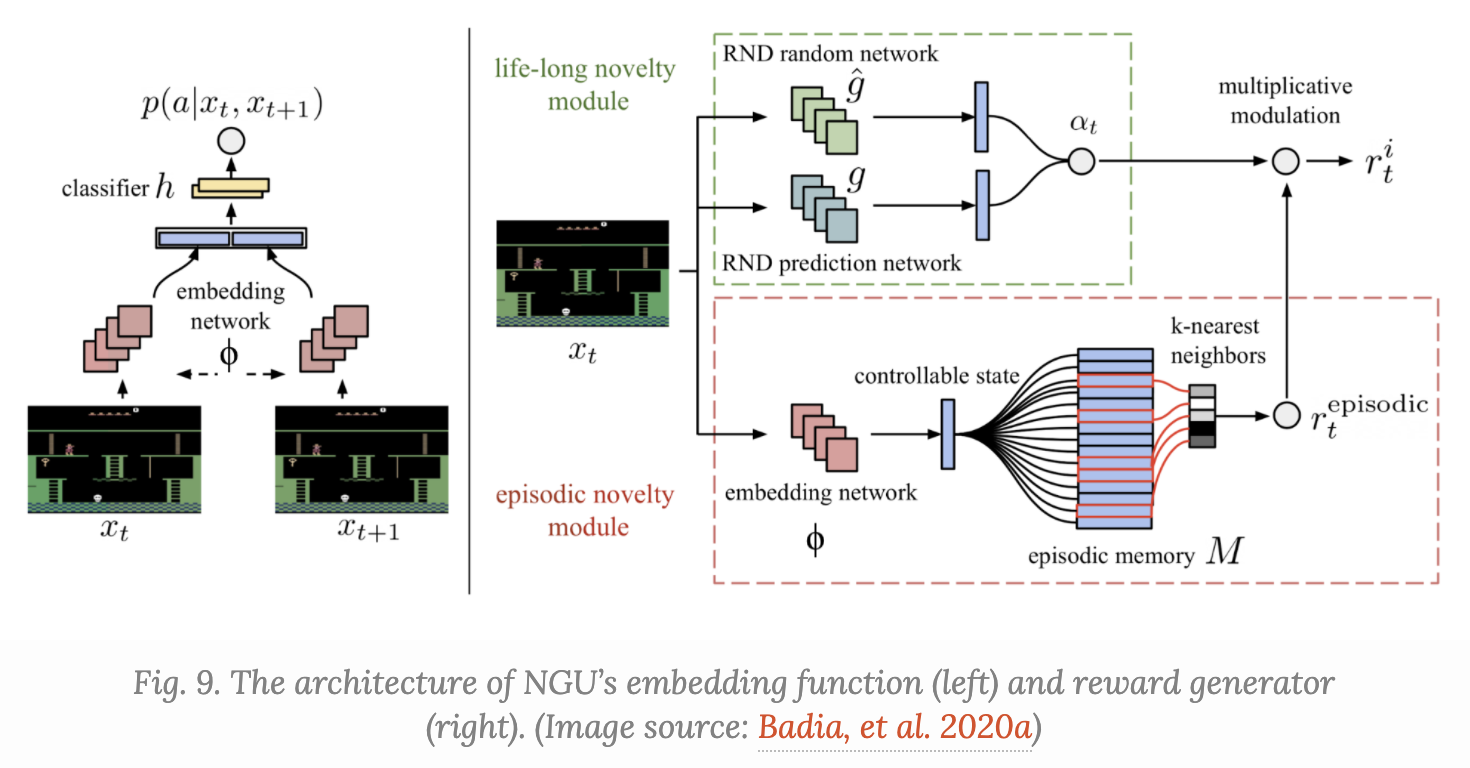
어쨌든 위 figure처럼 episodic novelty module이라고 하는 것을 사용하는데, 아래와 같은 프로세스로 이뤄져 있다.
1) current state를 embedding network로 embedding하고
2) episodic memory M에 add 한다.
3) current state와 episodic memory M 사이의 distance를 구해 episodic reward로 이용한다.
이때 수식은 아래와 같고, d는 Euclidean distance를 의미한다.
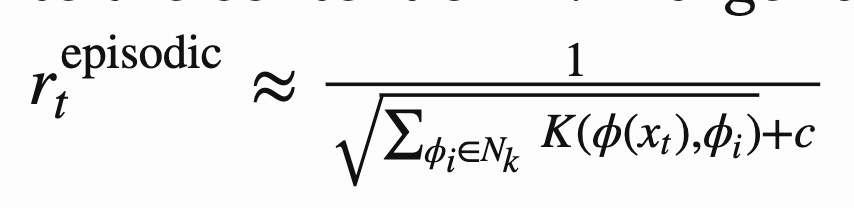
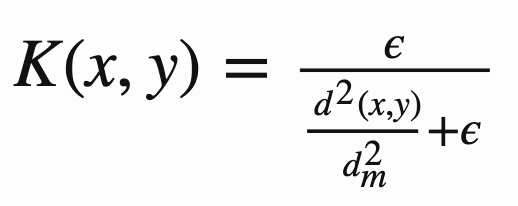
정리해보자면,
RND 부분을 통해서 non-episodic하게 exploration 진행한다면,
episodic novelty module을 이용하여 episode 내에서도 new state를 발굴하려는 exploration을 진행하는 거 같다.
github :
https://github.com/Coac/never-give-up/blob/main/train.py
https://github.com/opendilab/DI-engine/
def compute_intrinsic_reward(
episodic_memory: List,
current_c_state: Tensor,
k=10,
kernel_cluster_distance=0.008,
kernel_epsilon=0.0001,
c=0.001,
sm=8,
) -> float:
state_dist = [(c_state, torch.dist(c_state, current_c_state)) for c_state in episodic_memory]
state_dist.sort(key=lambda x: x[1])
state_dist = state_dist[:k]
dist = [d[1].item() for d in state_dist]
dist = np.array(dist)
# TODO: moving average
dist = dist / np.mean(dist)
dist = np.max(dist - kernel_cluster_distance, 0)
kernel = kernel_epsilon / (dist + kernel_epsilon)
s = np.sqrt(np.sum(kernel)) + c
if np.isnan(s) or s > sm:
return 0
return 1 /train 코드 내에 embedding network 까지 다 정의되어 있어서 쉽게 사용이 가능할 거 같다.
[Reference]
What is the difference between continuing (non-episodic) and episodic reinforcement learning tasks? What is the role of the disc
Answer: It’s basically the same as finite horizon versus infinite horizon in dynamic programming. In the infinite horizon case, the discount factor is mathematically convenient because it forces the reward series to be absolutely convergent. In the finit
www.quora.com
https://www.quora.com/How-can-I-distinguish-between-episodic-and-continuous-tasks
How can I distinguish between episodic and continuous tasks?
Answer (1 of 2): Episodic tasks mean that there is at least one (there may be more) that is terminal, meaning that the probability of going from this state to any other state is zero or, equivalently, that the probability of remaining in this state is one,
www.quora.com
http://sanghyukchun.github.io/96/
Machine learning 스터디 (20-1) Multi-armed Bandit - README
들어가며 이 글에서는 reinforcement learning의 한 갈래 중 하나인 Multi-armed Bandit에 대해 다룰 것이다. Multi-armed Bandit이 어떤 문제인지에 대해 간략히 설명한 다음, 좀 더 formal하게 문제를 정의하고, 이
sanghyukchun.github.io
https://velog.io/@nawnoes/10.-RNDExploration-by-Random-Network-Distillation
10. RND(Exploration by Random Network Distillation)
OpenAI에서 발표한 Exploration에 대한 논문. Atari 게임에서 어려운 게임인 몬테주마의 복수(Montezuma’s Revenge) 게임에서 SOTA를 기록한 논문이다. 지금까지 여러 강화학습 알고리즘이 있었지만 Reward가 S
velog.io
Exploration Strategies in Deep Reinforcement Learning
Exploitation versus exploration is a critical topic in reinforcement learning. This post introduces several common approaches for better exploration in Deep RL.
lilianweng.github.io
https://ssjin.tistory.com/entry/RL-Never-Give-Up-Learning-Directed-Exploration-Strategies-ICML-2020
[RL] Never Give Up: Learning Directed Exploration Strategies, ICML 2020
12/31 세미나했던것. 영어로 작성했던 ppt라 영어로 포스팅ㄷㄷ 핵심은 exploration을 좀 더 잘하기위해 intrinsic reward를 어떻게 줄것인지에 초점. 그냥 multi agent들로 막 exploration해서만은 이 경지에 이.
ssjin.tistory.com
'관심있는 주제 > 강화학습' 카테고리의 다른 글
| Alpha Zero 논문 리뷰 (2) | 2023.10.25 |
|---|---|
| torch tensor concat 하는 방법 (0) | 2023.01.10 |
| Diversity is all you need: Learning skills without a reward function (0) | 2020.10.01 |
| Connections Between GANs and AC Methods in RL (2) | 2019.08.04 |
| Deep RL based Recommendation with Explicit User-Item Interactions Modeling (0) | 2019.05.09 |