논문 제목 : Proximal Policy Optimization Algorithms

논문 저자 : John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimow
Abstract
- Agent가 환경과의 상호작용을 통해 data를 sampling 한다.
- Stochastic gradient ascent 이용해 surrogate objective function을 optimize 한다.
위 두 가지를 번갈아 수행한다.
- Data sample마다 gradient를 update 하는 기존 방법과 달리, novel objective function이 mini batch update를 통해 multiple update를 가능하게 한다.
1 Introduction
- First-order optimization을 이용해 data efficieny와 TRPO의 performance를 가져온다. (2차 근사를 이용하는 TRPO보다 1차 근사를 이용하는 PPO가 구현이 더 쉽다. )
- Lower bound와 같은 policy performance을 비관적으로 추정한 probability ratio를 clip 하는 novel objective function을 제안한다.
Make the first order derivative solution, like gradient descent, closer to the second order derivative solution by adding soft contraints. => 이거는 PPO 공부할 때 어디서 보고 설명이 좋길래 적어놨는데 어디서 봤는지 기억이 안나는...
** Quick Facts **
- PPO는 on-policy 알고리즘이다. (학습하는 policy와 행동하는 policy가 같다.)
- PPO는 continuous 와 discrete action spaces를 가진 환경에서 모두 사용 가능하다.
2 Background : Policy Optimization
2.1 policy gradient
- Policy gradient method는 policy gradient의 추정을 계산하고 이를 stochastic gradient ascent 알고리즘에 plug in 한다.
- PG methods은 실험적으로 destructively large policy updates를 이끈다. => 즉 너무 큰 policy의 변화를 유도한다는 것.
2.2 Trust Region Methods
- TRPO에서는 policy update를 constraint 하여 objective function을 maximize 한다.
- Constraint로 인하여 excessive large policy update가 방지된다.
- 이론적으로 TRPO는 constraint대신 penalty를 사용하는 것을 제안하지만, beta를 찾는 것이 어렵기 때문에 constraint를 이용한다.
Hence, goal을 달성하기 위해서는 beta(fixed penalty coefficient)를 찾고 objective equation을 optimize 하는 것으로는 충분하지 않다. ==> 그래서 PPO가 등장했다?
3 Clipped Surrogate Objective
-TRPO의 surrogate objective function은 아래와 같다.

- Constraint없이 위 objective function을 최대화하는 것은 excessively large policy를 가져온다. 따라서 이 논문에서는 어떻게 objective function을 수정하고, policy 변화에 penalty를 줄지 얘기한다.

- 위 수식의 first term은 L^(CPI)의 min이다.
- Second term은 [1-epsilon, 1+epsilon] 밖에서 r_t를 이동하려는 incentive를 제거하는 probability ratio를 clip하여 surrogate objective function을 수정한다는 의미
- Finally, clip된 부분과 unclip된 부분의 min을 취해 final objective function이 lower bound가 된다. (on the unclipped)
- Objective improve를 make할 때의 변화는 무시하며, objective worse를 make할 때의 변화만을 include한다.
==> min을 취하는 것이 목적이므로 굳이 improve한 경우를 취하지 않는 다고 이해했다.
- The probability ratio r은 advantage A가 양수냐 음수냐에 따라 1-epsilon 또는 1+epsilon에서 clip된다.

- A>0 이고 r>0 이면 위 수식에 따라 L^CLIP가 계속 증가한다. 이것을 너무 증가하지 않도록 clip한다.
- A<0 이고 r>0 이면 위 수식에 따라 L^CLIP가 계속 감소한다. 이것을 너무 감소하지 않도록 clip한다.
==> goal이 excessively large policy updat를 방지하는 것이니까?
(라고 이해함)
4 Adaptive KL Penalty Coefficient
- Clip과 다른 접근법으로 KL divergence penalty가 있다.
- 이것은 clipped surrogate objective 대신 KL divergence의 penalty를 이용하며, 각 policy update에 대한 KL divergence d_targ의 target value를 얻기 위해 페널티 계수를 적용한다.
- 알고리즘을 수행함에 있어 step one and two가 존재한다. (in each policy)
-
Step 1 : minibatch SGD의 여러 epochs를 이용해, KL-penalized objective function을 optimize한다.

-
Step 2 : d와 d_targ의 비교를 통해 Beta를 update한다. 이 Beta는 다음 policy update에 사용된다.

- 이 방법에서 d와 d_targ의 차이가 있을 때 효과적으로 policy를 upate하는 것을 볼 수 있다. 하지만 이러한 상황은 매우 드문 경우이며 beta는 빠르게 adjust된다.
- Beta의 초기 값은 hyperparameter이지만 beta가 빠르게 adjust되기 때문에 크게 중요하지는 않다.
5 Algorithm
- Variance-reduced advantage-function을 계산하기 위한 대부분의 기술은 learned state-value function V(s)를 사용한다. 예를 들어, generalized advantage estimation [Sch + 15a] 이나 finite-horizon estimator [Mni + 16]이 있다.
- 만약 policy와 value function 사이에서 parameters를 공유하는 neural network architecture를 이용한다면, policy surrogate와 value function error term을 combine하는 loss function을 이용해야만 한다. 또한 이 loss function에 entropy bonus를 추가하여 충분한 exploration이 될 수 있도록 한다.
- PPO에서 제시하는 objective function은 아래와 같다.
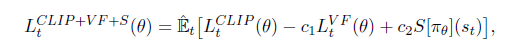
여기서
-
c_1, c_2 : coefficients,
-
S : an entropy bonus
-
L^VF : a squared-error loss


PPO algorithm은 아래와 같다.

- 아래는 MC러닝의 강화학습 연구소라는 블로그에서 친절하게 한글로 바꿔준 알고리즘 pseudo code이다. OpenAI에 올라와 있는 PPO 설명을 번역해 주셨다.

- 아래는 지금까지 나왔던, clip이나 penalty 없을 때, clipping 그리고 KL penalty 인 경우에 따른 objective이다.

6 Conclusion
- 이 알고리즘은 안정적이고 TRPO 보다 구현이 쉬우며 TRPO의 장점을 가지고 있다.
- 더 일반적인(general) 상황에 적용이 가능하다. (예를 들어, policy와 value function에 대한 공동 architecture를 이용할 때)
- 그리고 더 좋은 성능을 가진다.
'관심있는 주제 > 강화학습' 카테고리의 다른 글
| Exploration 방법론(RL) (0) | 2022.01.08 |
|---|---|
| Diversity is all you need: Learning skills without a reward function (0) | 2020.10.01 |
| Connections Between GANs and AC Methods in RL (2) | 2019.08.04 |
| Deep RL based Recommendation with Explicit User-Item Interactions Modeling (0) | 2019.05.09 |
| DDPG(Deep DPG) (0) | 2019.04.24 |