논문 제목 : Continuous Control with Deep Reinforcement Learning

논문 저자 : Timothy P.Lillicrap, Jonathan J.Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver&Daan Wierstra
Abstract
- DDPG는 actor-critic, model free, off-policy algorithm이다.
- Deterministic policy gradient를 기반으로 한다.
- Continuous action space에서만 가능하다.
- DDPG is able to find policies whose performance is competitive with those found by a planning algorithm with full access to the dynamics of the domain and its derivatives.
1 Introduction
1.1 DQN
- Raw pixel input을 사용함으로써 high-dimensional observation spaces에 대한 문제를 풀었지만, discrete & low-dimensional action spaces에서만 사용 가능하다.
- Continuous action space를 다루기 위해선 every step마다 iterative optimization process를 거쳐야 한다.
- DQN을 continuous action space에 적용하기 위해서 단순하게 action space를 discretize할 수 있지만, 많은 한계가 존재한다.
- 예를 들어, 7개의 관절을 가진 로봇 팔이 있다고 가정해보자. 가장 coarsest discretization은 각 관절이 {-k, 0 , k}와 같은 3개의 action을 갖는 경우이다. 이때 3 * 3 * 3 * 3 * 3 * 3 * 3 = 2187 가지의 dimension을 가지는 action space가 만들어진다.
- 이처럼 경우에 따라 action space가 exponential하게 늘어나게 되며, 너무 큰 action space를 가지면 충분한 explore를 하기 어렵다는 단점이 있다.
따라서 DDPG는 DQN의 장점과 actor-critic approach를 합칩니다. 그 두가지를 정리하자면 아래와 같다.
-
The network is trained off-policy with samples from a replay buffer to minimize correlations between samples
-
The network is trained with a target Q network to give consistent targets during temporal difference backups. (update하는 동안 target을 안정적으로 만들어준다.)
- 이러한 접근의 key feature는 간단함이다. 다시 말하자면 DDPG는 복잡하지 않은(straightforward) actor-critic architecture와 적게 움직이는 learning algorithm만을 필요로 한다.
- 그리고 이를 이용하면, 더 어려운 문제와 대규모 networks를 구현하고 확장하는 것이 쉬워진다.
2 Background
2.1 Notation

2.2
-
State s_t에서 action a_t를 취했을 때의 expected return :
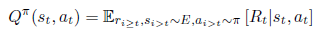
-
Expected return에 bellman equation 취한 경우 :

-
만약 target policy가 deterministic policy일 경우, 아래와 같다.

-
Q learning

- 최근, large neural networks을 function approximator로 효과적으로 사용하기 위해 Q-learning을 적용하였다.
- Q-learning을 확장하기 위해 replay buffer와 target network를 이용하며, 그에 대한 설명은 아래에 있다.
3 Algorithm
Continuous spaces에서 greedy policy를 찾기 위해서는 모든 timestep에서 optimization fo a_t를 요구하기 때문에, continuous action spaces에 바로 Q-learning을 적용하는 것은 불가능하다. 따라서 DDPG는 DPG algorithm에 근거한 actor-critic approach를 이용한다.

3.1 Replay buffer
- Large state spaces에서 학습하고 generalize하기 위해선 non-linear function approximators가 필수적이다. 하지만 이것이 수렴한다는 보장이 없다.
- NFQCA는 수렴 안정성을 위해 batch learning을 사용한다. NFQCA의 minibatch version은 original DPG와 같다.
- 이 논문에서 제안하는 것은, large state와 action spaces online에서 neural network function approximators을 사용한 학습을 allow하는 DQN과 DPG의 결합이다.
- 강화학습에 neural networks를 이용할 때 한가지 challenge는 대부분의 최적화 알고리즘(optimization algorithms)이 samples들이 독립적(independently)이고 동일하게 분포(identically distributed)된다는 것을 가정한다는 것이다.
- 하지만 samples가 환경에서 순차적으로 exploring하는 것으로부터 생성될 때(be generated), 이 가정은 더이상 유지되지 않는다.
- 또한, hardware optimizations을 효율적으로 사용하기 위해서는 online보다 minibatch로 학습하는 것이 필수적이다.
- 이러한 문제를 해결하기 위해서 replay buffer를 이용한다.
즉 DDPG에선 samples 사이의 correlations을 줄이기 위해 replay buffer를 사용한다.
3.2 Soft target update
- Neural networks에 직접 Q-learning을 구현하는 것은 안정적이지 못하다.
- Update되는 Q network가 target value의 계산에도 사용되기 때문에, Q update는 발산하는 경향이 있다.
- 따라서 이 논문의 solution은 'use soft target update for the stability of learning' 이다.
- Soft target update
-
바로 weights를 copy하는 대신, target value 를 계산하는데 사용되는 actor와 critic network를 copy한다.
-
이 target network의 weights는 학습된 networks를 천천히 추적하도록 함으로써 update 된다.

다시 말하면, target values를 천천히 변하도록 제한해 학습의 안정성(stability of learning)을 높이는 것입니다.
Target network는 value estimations의 propagation을 지연시키기 때문에 학습이 느려질 수 있지만, 학습의 안정성을 위해선 중요한 부분이다.
3.3 Batch normalization
- Low dimensional feature vector observations로부터 학습 할 때, observation의 다른 성분은 상이한 물리적 단위를 가질 수 있고 그 범위는 환경에 따라 다를 수 있다.
- 이것은 서로 다른 state values의 scale을 가진 환경에 걸쳐 generalize하는 hyper-parameters를 찾기 어렵게 만든다. 또한 효율적으로 학습하기도 어렵게 만든다.
즉 서로 크기가 다른 feature를 state로 사용할 때, neural network는 일반화에서 어려움을 겪는다.
- 이러한 문제를 해결하기 위해 batch normalization을 이용한다.
3.4 Noise process
- Continuous action spaces에서의 주된 과제는 exploration이다.
- DDPG에서는 지속적인 exploration을 위해 action에 noise를 준다.

3.5 Pseudocode

4 Conclusion
- 이것은 최근 딥러닝과 강화 학습의 발전으로 부터 나온 insights를 합친 것으로, continuous action spaces에서 다양한 domain의 문제들을 로버스트 하게 해결한다.
- Non-linear function의 사용은 수렴을 보장하지 않는다. 하지만 이 실험의 결과에서 환경의 어떠한 수정(조작)없이 안정적으로 수렴하는 것을 볼 수 있다.
- Atari domain에선 DQN보다 적은 step으로 solutions을 찾았다. (더 빨리 수렴했다.)
- 시간이 충분하다면, DDPG는 더 어려운 문제들도 해결할 수 있을 것이다.
- DDPG가 solution을 찾기 위해선, 많은 수의 episodes가 필요하지만, 향후 robust model-free approach는 이러한 한계를 물리칠 정도의 중요한 요소가 될 것이다. (large system의)
'관심있는 주제 > 강화학습' 카테고리의 다른 글
| Exploration 방법론(RL) (0) | 2022.01.08 |
|---|---|
| Diversity is all you need: Learning skills without a reward function (0) | 2020.10.01 |
| Connections Between GANs and AC Methods in RL (2) | 2019.08.04 |
| Deep RL based Recommendation with Explicit User-Item Interactions Modeling (0) | 2019.05.09 |
| Proximal Policy Optimization Algorithms(PPO) (0) | 2019.04.22 |