논문 제목 : Deep Reinforcement Learning based Recommendation with Explicit User-Item Interactions Modeling

본 게시글은 DNN for YouTube Recommendation논문과 actor-critic에 대한 어느 정도의 이해를 필요로 합니다.
Abstract
- Recommendation system은 collaborative filtering, matrix factorization, logistic regression, factorization machines 등 다양한 방법이 있다.
- 하지만 위와 같은 방법들은 두 가지 한계가 존재한다.
1) User의 preference가 계속 변하지 않는다고 가정한다.
2) 직전의 reward를 최대화하는 것에 집중하며, 추천한 items이 click 또는 consume 됐는지 여부에만 집중한다.
- 본 논문에서는 이러한 한계를 극복하기 위해 ‘novel recommendation framework based on deep reinforcement learning’ (이하 DRR)을 이용한다.
- 그 중에서도 ‘Actor-Critic’ reinforcement learning을 이용할 예정이며, 이는 user와 recommender systems 사이의 상호작용을 모델링하는 것에 활용된다.
1 Introduction
Abstract에서 얘기한 한계에 대해 자세히 살펴보도록 하자.
-
먼저, user의 preference가 변하지 않는다고 가정할 때, 잘못된 상품을 추천할 확률이 높아진다. 본 논문에서는 user의 preference가 dynamic하다고 말한다. 그러므로 user의 dynamic preference는 good recommendation가 sequential decision making process로서 모델링 되어야 한다고 제안한다.
-
Sequential decision: to take both the immediate and long-term reward into consideration
-
두번째로, immediate reward에만 신경 쓰는 것은 long-term contributions를 무시할 가능성이 있다. 만약 long-term benefits이 클 경우, 결과에 상당히 crucial한 영향을 준다.
-
최근, 강화학습은 dynamic modeling과 long-term planning을 모두 필요로 하는 various challenging scenarios에서 큰 잠재력을 보여주고 있다.
-
DQN과 같이 Q-value를 이용하는 recommendation system도 있지만, 너무 큰 action space에서는 비효율적인 것을 확인할 수 있다.
-
따라서 이러한 비효율성도 극복하고, representation으로 continuous parameter vector를 이용하는 DDPG를 사용할 것이다.
-
Continuous parameter vector를 이용하는 이유: Policy-based approach는 input을 state로 output을 action으로 받아 policy를 generate 한다. 또한 large action space problem을 해결하려면 continuous item embedding space에서 state를 모델링해야 한다. Input이 continuous일 때, output이 discrete이면 둘 사이의 간격으로 인해 성능이 저하될 수 있다. 따라서 continuous action space 이용하며 recommendation은 items의 각 scores로 순위를 매겨 generate한다.
본 논문에서는 강화학습 기반 추천 기술을 large-scale scenario에 적합하게 만들기 위해 DRR Framework를 제안한다. 이는 users와 items 간의 상호작용을 신중하고 explicitly하게 모델링하여 state representation을 학습한다.
2 Preliminaries
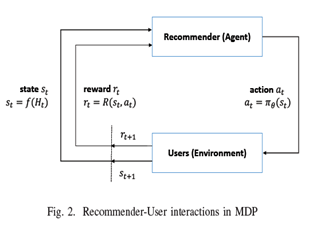
-
State S: user’s positive interaction history with recommender.
-
Actions A: continuous parameter vector (모든 candidate items의 ranking scores를 결정, Top-N items이 추천됨)
-
Transitions P: State는 user의 긍정적 상호작용 기록의 representation이다. 그러므로 한 번 user의 feedback이 들어오면 state transition이 determine된다.
-
Reward R: user’s feedback(satisfaction)
-
Discount rate γ : factor measuring the present value of long-term rewards

-
Actor-critic 기반 DRR은 3가지 필수 요소가 있다.
1) Actor network
· main network로 policy network라고도 한다.
· User state를 input으로 간주한다.
· Embedding한 input은 user에 대한 요약된 representation s로 공급된다.
· 2개의 ReLU layers와 하나의 Tanh layer를 이용해 representation s를 actor network의 output인 action a로 transform 시킨다. (기존 DNN은 3개의 ReLU laye
· Top ranked item이 user에게 추천된다.
2) Critic network
· DQN의 network이다.
· User state representation module과 actor network의 action a로 generate된 user state를 input으로 간주한다.
· Output은 Q-value이며 scalar이다.
· Q-value에 따라 actor network의 parameters가 업데이트 되며, 이는 action의 성능을 향상시킨다.
· Policy update에 관련한 식은 아래와 같다.
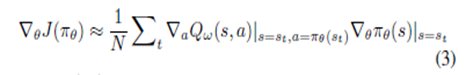
3) State representation: actor network와 critic network에서 중요한 역할을 한다. 이것은 state를 모델링하는 데에 필수적이며, features간 상호작용을 명확하게 모델링하면 추천 시스템의 성능을 향상시킬 수 있다.
-
DRR-ave: state를 모델링하는 structure로 평균을 이용한다.

1) H를 weighted average pooling layer에 의해 변형시킨다.
2) 변형시킨 vector는 input user와 상호작용을 모델링하는 것에 사용된다.
3) User의 embedding과 items의 average pooling layer를 합쳐 state representation을 만든다.
H: n개의 item들로 이루어진 집합 {i1,i2, … , in}
3 Algorithm & Conclusion
-
DRR은 sequential decision making process와 actor-critic의 적용으로 recommendation을 해결한다.
-
Actor-critic algorithm은 immediate와 long-term reward를 모두 focus on 할 수 있다.

'관심있는 주제 > 강화학습' 카테고리의 다른 글
| Exploration 방법론(RL) (0) | 2022.01.08 |
|---|---|
| Diversity is all you need: Learning skills without a reward function (0) | 2020.10.01 |
| Connections Between GANs and AC Methods in RL (2) | 2019.08.04 |
| DDPG(Deep DPG) (0) | 2019.04.24 |
| Proximal Policy Optimization Algorithms(PPO) (0) | 2019.04.22 |